2. 进程与进程 API
程序本身只是存储在磁盘上面的一些指令(或静态数据)。操作系统通过提供称作 进程(Process) 的抽象来让程序运行发挥作用。一言以蔽之,进程即运行中的程序。
什么是进程?
但为了具体理解什么是进程,我们需要考察进程的 机器状态(Machine State),即程序在运行时可以读取或更新的内容,这包括:
- 地址空间(Address Space):进程可以访问的内存。
- 寄存器:包括通用寄存器与一些特殊寄存器,后者的例子包括 程序计数器、栈指针、帧指针。
- I/O信息:满足程序访问硬盘等可持久化设备的需求。
进程 API
操作系统必须提供一些控制进程的方法,这被称作 进程 API。其必须包括如下几类接口:
- 创建
- 销毁
- 等待
- 其他控制,例如暂停与恢复
- 状态
我们以 Unix 系统的进程 API 为例进行讲解:
fork()
系统调用 fork() 用于创建进程。看如下的示例代码:
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
perror("fork failed!");
return 1;
}
else if (pid == 0) {
// 子进程代码
printf("Hi! I'm child process,my PID=%d\n", getpid());
}
else {
// 父进程代码
printf("Hi! I'm father process,my PID=%d\n", pid);
}
return 0;
}
在 Unix 系统中,每个进程都有一个 进程标识符(Process Identifier,PID)。对某个进程的操作必须通过 PID 来指明。
在本例中,进行 fork() 系统调用创建子进程后,在操作系统的视角 有两个完全一样的程序在运行,它们都从 fork() 调用中返回。也即,创建的子进程不会从 main() 开始执行,而是直接从 fork() 中返回并继续执行后续代码。两个进程拥有独立的地址空间、寄存器、程序计数器等,然而这并不代表子进程拷贝了父进程。这与 fork() 地址的返回值有关:
- 父进程:返回子进程的PID(>0)
- 子进程:返回0
- 返回值<0表示创建失败
因此,上面这段程序的运行结果为:
Hi! I'm child process,my PID=1234
Hi! I'm father process,my PID=1235
或
Hi! I'm father process,my PID=1235
Hi! I'm child process,my PID=1234
具体会出现哪种结果是 不确定的,这取决于调度程序的调度顺序。顺带一提,这种不确定性会引发许多将在并发章节讨论的问题。
wait()
系统调用 wait() 可以用于父程序等待子程序执行完毕。其拓展版本 waitpid() 可以等待特定程序的执行。看如下的示例代码:
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
perror("fork failed!");
return 1;
}
else if (pid == 0) {
// 子进程代码
printf("Hi! I'm child process,my PID=%d\n", getpid());
}
else {
int wc = wait();
// 父进程代码
printf("Hi! I'm father process,my PID=%d\n", pid);
}
return 0;
}
一般来说此时父程序执行到 wait() 时会被阻塞等待子程序执行完成后继续执行。因此该程序的输出结果具有确定性:
Hi! I'm child process,my PID=1234
Hi! I'm father process,my PID=1235
wait() 何时返回?
系统调用 wait() 在子进程结束后返回只是一种最常见的情况,在某些情况下 wait() 会在子程序结束前返回。具体而言:
| 场景 | 返回值 | 错误码 (errno) |
|---|---|---|
| 子进程终止 | 终止子进程PID | - |
| 被信号中断 | -1 | EINTR |
| 没有子进程可等待 | -1 | ECHILD |
选项WNOHANG+无子进程终止 |
0 | - |
wait() 系统调用同样有返回值,如果执行成功则返回子进程的 PID,如果有错误发生则返回 -1。该系统调用可以用于回收子进程资源以防止僵尸进程(见下面进程状态,且获取子进程退出状态(传参数 NULL 代表不关心这一点)。
exec()
exec() 系统调用同样用于创建进程,其代表了一类执行其它程序的系统调用族,如 execl(),execv() 等等。且允许子进程执行与父进程不同的程序,见如下示例代码:
#include <stdio.h>
#include <unistd.h>
int main() {
printf("Executing ls command...\n");
// 替换当前进程为/bin/ls
execl("/bin/ls", "ls", "-l", NULL);
// 只有exec失败才会执行到这里
perror("exec失败");
return 1;
}
系统调用 exec() 会从可执行程序中加载代码和静态数据,用其 覆盖 当前程序的代码段、静态数据,堆、栈等其它内存空间被重新初始化后,执行新的程序,但进程的 PID 保持不变。也即, exec() 没有创建新的程序,而是用新程序替换当前进程的内存空间。也因此,对 exec() 的调用一旦成功,就不会返回。
因此,上述代码成功执行的结果为:
Executing ls command...
<当前目录下执行 ls -l 命令的结果>
这段代码成功执行时的输出结果会是什么?
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid < 0) {
perror("fork failed!");
return 1;
}
else if (pid == 0) {
// 子进程执行新程序
execl("/bin/date", "date", NULL); // 替换为date命令
perror("exec failed!"); // 仅exec失败时执行
return 1;
}
else {
// 父进程等待子进程
printf("Father waiting child (PID=%d)...\n", pid);
wait(NULL); // 阻塞等待
printf("Child Process ended.\n");
}
return 0;
}
上述只是 Unix 系统最常见的与进程交互的系统调用,还有其它的系统调用,例如可以向进程发送信号的 kill()。还有一些有用的 Unix CLI 工具,例如 ps 可以查看当前正在运行的进程,top 查看进程占用 CPU 或其它资源的情况等等。
这些系统调用的功能虽然奇怪,但在 Unix 系统中十分实用,尤其是当实现 shell 时:shell 启动后输出一个命令提示符,我们可以向 shell 输入命令,shell 通过 fork() 创建一个子进程,在子进程中使用 exec() 执行命令,在父进程中通过 wait() 等待子进程执行完成,然后继续重复上述步骤。
此外,shell 允许用户通过 < 或 > 符号进行流的重定向。具体原理就是在 exec() 后关闭了系统的标准输入流或标准输出流,然后打开用户执行的重定向对象。新打开的文件会占用可用的标准输入或标准输出的文件描述符(链接待补充)。
Unix 的 管道(Pipe) 也是通过类似方式实现的,不过其有一个专门的 pipe() 系统调用。此时一个进程的输出与另一个进程的输入被链接到了同一个 内核管道 上,这允许许多程序串联到一起共同完成某项任务。
虚拟化 CPU
前面 提到过,操作系统能提供机器具有许多 CPU 的假象允许多个进程同时运行。
操作系统通过 虚拟化 CPU 来提供这种假象。从实际结果来说,操作系统通过让一个进程运行一段时间,然后切换到其它进程来实现这一点。这是一种 时分共享(Time Sharing)技术。
时分共享与空分共享是操作系统共享资源使用的最基本的技术之一。正如名字所示,时分共享将某个资源分给某个实体使用一段时间,随后将资源分给另外一个实体使用一段时间,如此下去。CPU 与网络链路都是时分共享资源。与之对应的是空分共享,资源在空间上被划分给对应使用它的实体。磁盘空间是空分共享资源,这很显然,一旦将某块磁盘空间划分给某个文件,在该文件被删除前不可能将其划分给其他文件。
为了实现虚拟化,操作系统需要一些 机制(Mechanism) 与 策略(Policy)。机制是一些低级方法或协议,实现了需要的功能,即“How”的问题;策略是操作系统内做出某种决定的算法,负责解答'Which"的问题。具体到本例,机制负责实现某个程序运行一段时间后暂停,恢复另一个程序的运行的功能,这被称作 上下文切换(Context Switch);策略负责决定当一组程序需要在 CPU 上运行时,到底运行哪个程序,这被称作 调度策略(Scheduling Policy)。
操作系统也是一个程序,其会维护一些关键的数据结构来跟踪各种相关的信息。例如 进程列表 可以跟踪每个进程的状态与正在运行的进程的某些附加信息。此外,操作系统还必须跟踪被阻塞的进程,例如使用寄存器上下文保存阻塞程序的寄存器信息,以确保进程能够被唤醒。
进程创建
操作系统在提供进程这一抽象之外,还需要提供真正启动程序,将程序转化为进程的方法。启动程序的详细经过如下:
- 程序最初以某种可执行文件格式存放在硬盘上。操作系统想要启动该程序,就要从硬盘中读取这些字节,将程序的代码与所有静态数据(例如初始化变量)加载到内存,进程的地址空间中。在早期的操作系统中这一过程是在运行程序前完成的,但现代操作系统通常采用“懒惰执行”的策略,只在程序需要加在某些代码或数据片段时再将其读取进内存中。
- 随后,操作系统为程序的 运行时 栈 与 堆 分配内存。在 C 语言中,栈区负责存放程序需要的局部变量、函数参数与返回地址等信息。操作系统也可能会用参数初始化栈区,这体现在
main()函数的argc与argv变量中。堆区负责为代码中的显式资源请求分配对应资源。程序通过调用malloc()来请求这样的空间,调用free()来释放。大量操作系统需要堆区分配资源存储数据。 - 操作系统还需要执行其它的初始化任务,例如与 I/O 相关的任务。在 Unix 系统中,每个进程都有三个默认打开的文件描述符,分别对应 标准输入流(
STDIN)、标准输出流(STDOUT) 与 标准错误流(STDERR)。 - 完成上述所有任务后,操作系统找到程序的入口点(如 C 的
main()),将 CPU 的控制权移交给程序,程序开始执行。
进程状态
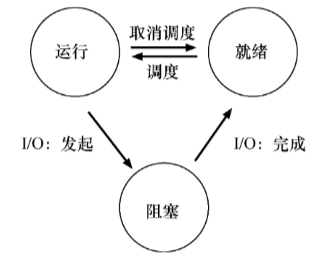
早期的计算机系统中,程序可以处于以下三种状态之一:
- 运行:程序正在 CPU 上运行
- 就绪:程序准备好运行,但没有真正运行
- 阻塞:程序执行了某些操作(例如发起 I/O 请求),直到某些事件发生才能准备好运行。
三种状态的状态机描述如下:
Unix 扩充了该描述,其核心程序状态包括:
- 运行 (Running / Runnable -
R): 进程正在 CPU 上执行,或者已经准备好执行,正在运行队列中等待 CPU 调度器分配时间片。 - 可中断睡眠 (Interruptible Sleep -
S): 进程正在等待某个事件(如等待 I/O 操作完成、等待信号量、等待网络数据、等待用户输入、等待子进程退出等)。关键特性是它可以被信号唤醒或中断。 - 不可中断睡眠 (Uninterruptible Sleep -
D): 进程同样在等待某个事件(通常是等待底层 I/O,特别是磁盘 I/O)。关键特性是它在等待期间不能被信号唤醒或中断(即使是SIGKILL也不行)。 - 停止 (Stopped -
T): 进程的执行被暂停(挂起),通常是因为收到了一个暂停信号(如SIGSTOP,SIGTSTP/ Ctrl+Z)。它可以被恢复信号(如SIGCONT)唤醒,继续执行。 - 僵尸 (Zombie -
Z): 进程已经终止执行(exit()系统调用),但其在内核中的进程描述符仍然保留着。保留的原因是为了让父进程能够读取该终止子进程的退出状态码。一旦父进程通过wait()或waitpid()系统调用读取了退出状态,僵尸进程的残留信息就会被内核彻底释放。 僵尸进程本身不消耗 CPU 和内存资源(代码、数据、堆栈等已释放),只占用一个 PID 和进程表中的一个槽位。
关于所有的 Unix 程序状态请执行 man ps 命令,见 PROCESS SELECTION BY LIST 一节。